遺伝子の構造と転写
体を構成するタンパク質は遺伝子上にコードされています。ひとの30億塩基対のゲノムDNA上には約数万の遺伝子が存在すると言われています。遺伝子の長さは数百ベースから数百キロベースまでさまざまです。遺伝子の5’側(DNA鎖のリン酸基が付いている方)にはプロモータと呼ばれる領域があります。
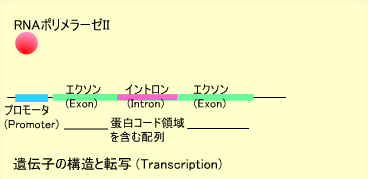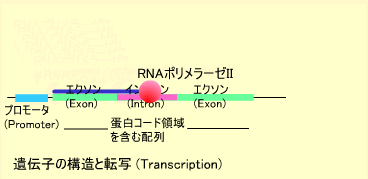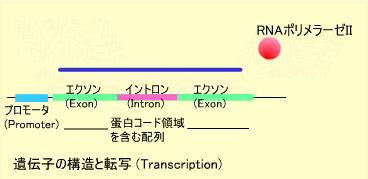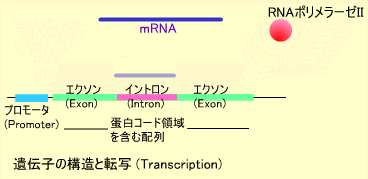
プロモータは転写開始点の上流近郊にあり、プロモータ部分にRNAポリメラーゼIIが結合します。この酵素はDNA鎖からRNA鎖を合成する酵素でいくつかの蛋白の複合体として働きます。RNAポリメラーゼIIはDNAを鋳型にRNAを合成します。遺伝子上にはエクソンとイントロンと呼ばれる領域があり、イントロン部分はGT・・・AGというコンセンサスで囲まれています。このイントロン部分が削られてメッセンジャーRNA(mRNA)になります。
このようにDNAからmRNAが作られることを転写(Transcription)といいます。mRNAの3’側(水酸基がある方)には数十から数百ベースのアデニン(A)が付加され、ポリAテイル(Poly-A tail)を構成します。RNA合成にはDNAのチミン(T)の代わりにウラシル(U)が使われます。
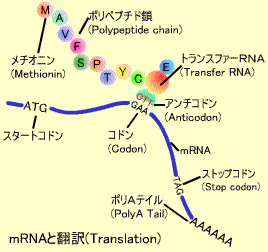
コドンと翻訳・蛋白合成
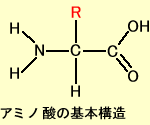
mRNA上のA, U, G, Cの配列はアミノ酸の鎖になり、蛋白として合成されます。これを翻訳(Translation)といいます。

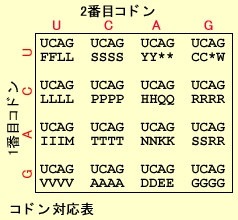
U(T)、C、A、Gの4つのリボ核酸の組み合わせはアミン酸をコードしています。これは3つごとの塩基のセットが1つのアミン酸に対応していますこれをコドン(Codon)といいます。
たとえばATGはメチオニン(M)、GAAはグルタミン酸(E)に対応しています。4種類の塩基を3つ組み合わせると(4種類X4種類X4種類=64種類)のアミノ酸をコードできますが、実際に蛋白を構成するアミノ酸は20種類しかなくいくつかのアミン酸のコードは重複しています(コドン対応表参照)。たとえばアルギニン(R)をコードするコドンは6つあります。アミノ酸以外に翻訳をストップさせるコードはUAA、UAG、UGAの3種類あります。
翻訳はコンセンサス配列の下流にあるメチオニン(M)から始まります。このペプチド鎖の合成はトランスファーRNA(tRNA)によって行われます。
20種類のそれぞれのアミノ酸をもったtRNAはコドンと相補的なアンチコドンを持っています。このアンチコドンがmRNA上のコドン配列を認識して対応するアミノ酸を順に結合していきます。スタートコドンからはじまった翻訳はストップコドンまで達すると蛋白合成がストップします。これら蛋白合成は細胞質中にあるリボゾーム(Ribosome)で行われます。
このように遺伝情報はDNA → RNA → 蛋白の方向に伝わります(セントラルドグマ)。
RNAエディティング (RNA Editing)
遺伝子(DNA)の情報はRNAを介して正確に蛋白に翻訳されますが、一部の遺伝子はRNAの段階で塩基の置換が酵素によって行われます。これにはAPOBリポ蛋白のC → U、グルタミン受容体ではA → I(イノシン)への変換が行われています。
この変換でアミノ酸配列が変わり、合成されたタンパク質の生理機能が変化します。